Below I discuss a curious feature that arises from the Markov property in an asset pricing model.
Asset returns 




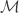

![(x^{[i]}, x^{[j]}) \in X \times X](https://s0.wp.com/latex.php?latex=%28x%5E%7B%5Bi%5D%7D%2C+x%5E%7B%5Bj%5D%7D%29+%5Cin+X+%5Ctimes+X+&bg=ffffff&fg=333333&s=0&c=20201002)
Realizations are normalized to be indicator functions 

Expected returns are ![\mathbb{E}[R_{t+1}|x_{t}] = r \cdot \mathcal{M}'1(x_{t})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BR_%7Bt%2B1%7D%7Cx_%7Bt%7D%5D+%3D+r+%5Ccdot+%5Cmathcal%7BM%7D%271%28x_%7Bt%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)



![\mathbb{E}[R_{t+1}|x_{t}] = r \cdot \mu_{0} + r \cdot \mathcal{M}_{\gamma}' 1(x_{t})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BR_%7Bt%2B1%7D%7Cx_%7Bt%7D%5D+%3D+r+%5Ccdot+%5Cmu_%7B0%7D+%2B+r+%5Ccdot+%5Cmathcal%7BM%7D_%7B%5Cgamma%7D%27+1%28x_%7Bt%7D%29+&bg=ffffff&fg=333333&s=0&c=20201002)
The rows of the transition matrix sum to one. Preservation of probability enforces a zero-sum condition 


The rows of 
The following simulations illustrate the phenomena of probability redistribution and dimension reduction for a Markov chain.
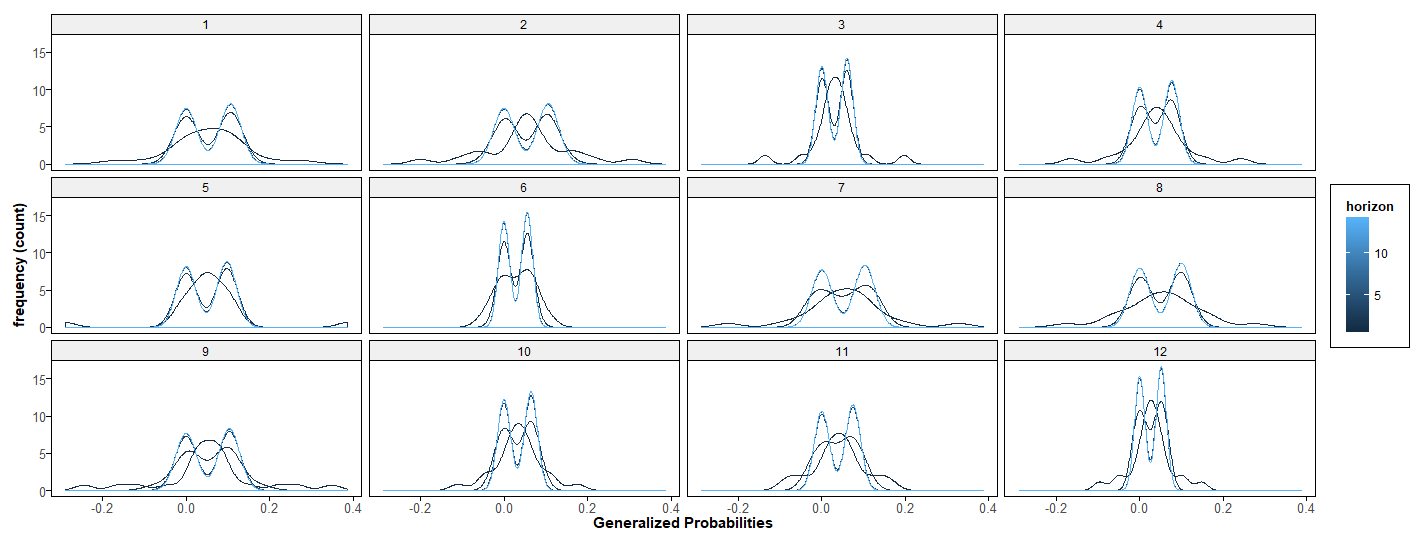
Each enumerated facet corresponds to a state of a 12-state Markov process. Integer powers of a Markov transition matrix capture transition probabilities over integer horizons. The plots show smoothed frequency counts of generalized probability values for successive horizons (black lines are early iterations – blue lines are later). The top panel shows distributions of probabilities relevant for forecasting k as k goes from periods 1-15, the lower shows horizons from 1 to 8.
The probability of each state is approximately bimodal for mid-range forecasts. For limiting long-run forecasts, the distributions are degenerate with all mass assigned to nonzero probabilities at the invariant values, represented by the right modes. Probability re-distributional effects are represented by the left modes.
An initial transition matrix, say 
In any finite sample, ergodic time series are generated by transition probabilities with some conditional dependence. Think, say, of the curve corresponding to the horizon h=8, and consider repetitions of a transition with the corresponding probabilities. This new process is also a Markov process, with an approximate 2-factor structure for dynamics. The trailing factor drives fluctuations that die out in large-time forecasts but are predictable in finite samples.
